
I bought a £50 security camera off Amazon to improve security at our home.
For a low cost unit it’s fairly capable, it works at night thanks to an array of IR LEDs, and the companion software allows you to control/view the feed from your phone, even outside your home network (which makes me slightly worried!).
It supports recording a video feed to a micro SD card, but I couldn’t actually prise the unit open to install one.
You can set a region of the image that you want to the camera to monitor. If it detects movement above a defined threshold it can alert you.
The camera can email you (couldn’t get that to work) or send you a push notification. This doesn’t include an image of what it saw, so it’s next to useless.
FTP
Not a problem, the camera can transfer images to an FTP site when movement is detected.
I set up a Raspberry Pi as an FTP server and started collecting images.
There are several how-tos for this on the web.
This is a great start, but my Pi will quickly fill up with pictures of my driveway, we should upload these images to the cloud.
Azure Blob Storage
I wrote a node.js application in TypeScript which picks up new files saved to the FTP site (by listening to the file system) and uploads them as blobs to Azure Blob Storage.
import nodewatch from 'node-watch'
import fs from 'fs'
import { BlobServiceClient } from '@azure/storage-blob'
const blobServiceClient = BlobServiceClient.fromConnectionString(AZURE_STORAGE_CONNECTION_STRING)
const containerClient = blobServiceClient.getContainerClient('frontdoor')
nodewatch(FTP_SERVER_PATH, { recursive: true }, handleFile)
const handleFile = (event: string, file: string) => {
if (event !== 'update') return
processFile(file)
}
const deleteFile = (path: string) => (
new Promise((resolve) => fs.unlink(path, resolve))
)
const processFile = async (file: string) => {
await containerClient
.getBlockBlobClient(blobName)
.uploadFile(file, { blobHTTPHeaders: { blobContentType: "image/jpeg" } })
await deleteFile(file)
}This was highly unreliable. The linux file system raises multiple events for file writes, and my code would pick up partially written files, despite numerous attempts to add delays and debounce code.
ONVIF
ONVIF is an industry forum that promotes standards for IP based security systems.
It basically means there’s a SOAP endpoint (remember that dead end?) that the camera exposes which allows you to control the camera. The standard includes zooming, panning, and adjusting the camera lens etc.., but my camera only allows you to take photos and capture the url for the live video feed.
This means I can use the FTP upload as a signal that the camera has detected movement, and then capture my own photo(s) for upload.
import onvif from 'node-onvif'
const discover = async () => {
const devices = await onvif.startProbe()
const discoveredDevice = devices[0] as any
if (!discoveredDevice) return
const xaddr = discoveredDevice.xaddrs[0] as string
const device = new onvif.OnvifDevice({
xaddr,
user: USERNAME,
pass: PASSWORD
})
await device.init()
return device
}
const device = await discover()
const takePhoto = async () => {
const res = await device.fetchSnapshot()
return res.body
}
const uploadStream = (blobName: string, stream: Buffer) => {
return containerClient
.getBlockBlobClient(blobName)
.upload(stream, stream.length, { blobHTTPHeaders: { blobContentType: "image/jpeg" } })
}
...
// when an image is uploaded to the FTP site, you can now call these lines to
// capture a photo and upload it
const image = await takePhoto()
await uploadStream(blobName, image)Nice! I now have complete, clean photos from the camera when movement is detected (or about 500ms after!) uploaded to the cloud.
Slack
But how do I view these images?
I started writing a static web app that can be installed as an icon in iOS. It uses CORS to connect to blob storage to retrieve the photos. This worked, but it wasn’t good enough.
Slack has a mobile (and desktop) app and easy integration points. It supports notifications and will display images. Let’s do it.
You need to register a web hook for a channel, which will give you a URL you can post messages to.
How do I securely share the image to slack though? Azure Blob Storage allows you to create a Shared Access Signature, which gives you a URL allowing you to download files from blob storage, whilst keeping the files otherwise private.
const { IncomingWebhook } = require('@slack/webhook')
const webhook = new IncomingWebhook(WEBHOOK_URL)
const sas = BLOB_STORAGE_SHARED_ACCESS_SIGNATURE
...
webhook.send({
attachments: [{
image_url: sas.replace('/?', `/container/${blobName}?`)
}]
})Now I get the photos posted to slack whenever movement is detected. Cool!
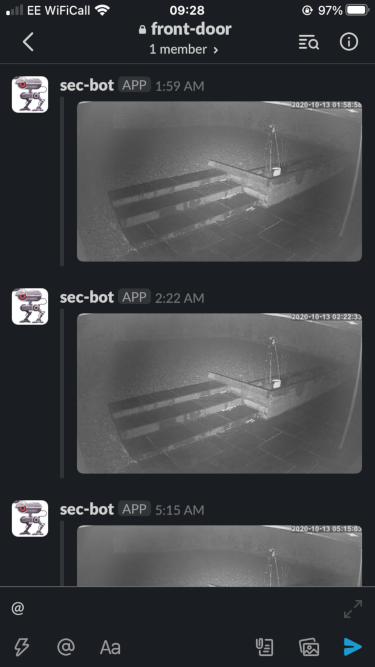
Azure Cognitive Services
There’s a problem. At dusk moths enjoy fluttering around in front of my camera. Spiders like to continually trip the motion detection (every 30 seconds) by building webs in front of it. The wind blows the sunflowers growing in the raised bed.
There are a lot of false positives.
I tried employing Azure’s Custom Vision Service, part of Cognitive Services. You can make use of Microsoft’s pre-trained image recognition models, and provide just a small set of your own classified images for it to learn from.
I uploaded 50 example images, half containing a person, half not and let it think about it for a couple of hours. After it had trained it’s model you get an API endpoint which you can then use to classify images.
The endpoint will take either the image in the request body, or a link to it. I might as well use the same URL I use for slack:
const postToAi = (url: string) => {
return new Promise<ClassificationResponse>((resolve, reject) => {
const body = JSON.stringify({
Url: url
})
const options = {
hostname: 'northeurope.api.cognitive.microsoft.com',
port: 443,
path: PREDICTION_PATH,
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Content-Length': body.length,
'Prediction-Key': PREDICTION_KEY
},
}
const req = https.request(options, (res) => {
let responseData = ''
res.on('data', chunk => responseData += chunk.toString())
res.on('end', () => resolve(JSON.parse(responseData)))
res.on('error', reject)
})
req.end(body)
})
}
export interface Prediction {
probability: number
tagId: string
tagName: string
}
export interface ClassificationResponse {
id: string
project: string
iteration: string
created: Date
predictions: Prediction[]
}
...
const classication = await postToAi(sas.replace('/?', `/frontdoor/${blobName}?`))
const prediction = classication.predictions.find(x => x.tagName === 'person')
if (((prediction?.probability || 0) * 100) > 50) {
// there seems to be a human in the image
// send a notification to slack as before...
}Now I get my results filtered to those that feature humans (mostly). It’s probably about 90% accurate.
To begin with I just posted the probability along with the image to slack so I could keep an eye on performance.
Next Steps
I might try to consume the live video feed and do my own movement detection. I’m also thinking of uploading this feed to blob storage and building a UI to watch it back.
I’d like to improve the classification, perhaps running the model locally rather than calling out to the Custom Vision API (you can export the trained models).
I’d also like to see where I could get by adding more cameras, perhaps they can cooperate?
It was fun pulling this code together. Perhaps I’ll do some refining and release it as open source…